Travel report to Meeting C++ 2018
Contents
- Introduction
- Workshop (Wednesday)
- Day 1 (Thursday)
- Day 2 (Friday)
- Middle Keynote: The Truth of a Procedure (Lisa Lippincott)
- Benchmarking C++ From video games to algorithmic trading (Alexander Radchenko)
- More Modern CMake - Working with CMake 3.12 and later (Deniz Bahadir)
- Higher order functions for ordinary C++ developers (Björn Fahller)
- C++ Concepts and Ranges - How to use them? (Mateusz Pusz)
- Day 3 (Saturday)
Introduction
Meeting C++ is a yearly conference taking place in Berlin. This year, i.e. 2018, it took place on 15th to 17th of November. It is organized by Jens Weller. As far as I know it is the biggest C++ conference in Europe. 650+ people attended this year. It was the third time I attended the conference. I took the train as usual starting early in the morning from Gothenburg and arriving in Berlin around 19 o’clock after switching trains in Copenhagen and Hamburg.
Daniel Eriksson and Dave Brown from Gothenburg also attended the conference. We are are all active in the Gothenburg C++ Meetup.
The venue of the conference is Vienna House Andels Hotel. I recommend staying in a room in the same hotel to save on travelling time in the morning and afternoon. I think most people attending the conference do this. The hotel feels quite new and the rooms are nice. I especially like that the air condition works properly since I have had bad experiences with too warm rooms in other hotels.


The main room of the conference is located in the basement of the hotel. All three keynote presentations took place there. The keynotes were spread out with one each day of the conference. No other presentations took place during the keynotes. The conference has four tracks. There is also a fifth special track where attendees can meet and discuss various subjects, e.g. there is one slot for user group organizers.
A lot of the talks have a strong template focus as I have already noted previous years. I had improved my template metaprogramming knowledge somewhat prior to this years conference which made it easier to follow the talks. I also attended the workshop day arranged by Nicolai Josuttis prior to the conference itself to boost my template knowledge a little bit more. The theme of the workshop was Modern C++ Template Programming.
I listened to 14 talks all in all not counting lightning talks. I also joined the Conan C++ quiz on the Thursday evening. I think it was a lot of fun even though we had great potential for improvement in my team with regards to the number of points we managed to acquire.
Below are my notes from the talks I attended.
Links:
Workshop (Wednesday)

Nicolai Josuttis packed a full day talking about templates. I learned more about two-phase translation, value categories, char array decaying and Class Template Argument Deduction (CTAD) among other things. He also talked about different ways to organize template code and lots of other stuff.
I finished one full day of templates workshop with @NicoJosuttis at @meetingcpp. 😅 A lot of information but I think the area is becoming more clear for me. 👍 I still need to learn more about what solutions make sense in my typical use cases. pic.twitter.com/SSOGyiTuCR
— Jacob Mossberg (@jcmossberg) 14 november 2018
Day 1 (Thursday)
Opening Keynote: The Next Big Thing (Andrei Alexandrescu)
Andrei Alexandrescu talked about Design by introspection. He talked about the C++ statement if constexpr. He thinks that the potential use cases for if constexpr would be more compelling if it would not introduce a scope. He would like to use if constexpr to select between different designs based on compile time conditions. Andrei also mentioned Policy based design.
I recently noted a blog post by Barry Revzin where he writes about the talk by Andrei.
Links:
A Little Order! (Fred Tingaud)

Fred Tingaud talked about STL sorting algorithms.
Algorithms:
Links:
Data-oriented design in practice (Stoyan Nikolov)

Stoyan Nikolov talked about data-oriented design. He said that the basic issue with Object Oriented Programming is that data is combined with operations which means that heterogeneous data is brought together. In data-oriented design data and operations are kept separate. The data is organized according to its use. Functions are used to work on the data. Data oriented design has mostly been used in games. Main selling point in my understanding is performance. The data is laid out in such a way in memory that the CPU intensive operations goes quicker.
Stoyan compared the Chromium browser engine (object oriented design) with the Hummingbird browser engine (data oriented design).
Potential downsides of data-oriented design:
- Correct data separation is hard
- Quick modification is difficult
Links:
- https://stoyannk.wordpress.com/
- Data-oriented design (Wikipedia)
- CppCon 2014: Mike Acton “Data-Oriented Design and C++”
std::variant and the power of pattern matching (Nikolai Wuttke)

Nikolai Wuttke talked about a programming style based on pattern matching using std::variant introduced in C++17. Nikolai compared different ways to handle states in a small example Space Game application. The traditional approach is to use an enum combined with state variables. Nikolai showed a different approach where possible states are stored in a std::variant and he makes use of std::visit to apply correct operation depending on current state. He went further and combined std::variant, std::visit with the experimental std::overload to write a match function to get something that is close to the native pattern matching available in Haskell and Rust.
Links:
- std::variant and the power of pattern matching (slides)
- https://github.com/lethal-guitar/VariantTalk
- C++ generic overload function (Revision 3), P0051R3, std::overload
Taming Dynamic Memory - An Introduction to Custom Allocators (Andreas Weis)

Andreas Weis talked about creating custom allocators for STL containers. He mentioned potential problems with the default allocator:
- Complex runtime behavior - What is the max memory usage for example?
- Shared global state - the single global allocator is a potential bottleneck.
He argued that not only performance is important but also whether the allocator acts in a predictable way. Andreas went on to discuss different types of allocators:
- Monotonic allocator
- Monotonic allocator with reclamation
- Stack allocator
- Monotonic allocator with extensions
- Pool allocator
- Multipool allocator
Links:
Day 2 (Friday)
Middle Keynote: The Truth of a Procedure (Lisa Lippincott)

Lisa Lippincott talked about how to apply formal reasoning on how a program works. She also discussed checkable proofs. Lisa presented the concepts using examples that she called “game of truth”, “game of necessity” and “game of proof”.

Benchmarking C++ From video games to algorithmic trading (Alexander Radchenko)

Alexander Radchenko talked about benchmarking C++ programs. He focused on games and high frequency trading applications.
Game companies develop custom profilers to analyze whole game sessions but also single frames. Network traffic is recorded to replay games. This can be used to reproduce performance measurements.
Throughput is most important in games whereas high frequency trading applications focus on low latency.
Tracing can be implemented with hardware timestamps or software timestamps. Hardware timestamps cost a few nanoseconds. Software timestamps cost more but are still cheap. std::chrono::high_resolution_clock can be used to create time stamps.
Alexander makes use of Jupyter notebooks to analyze and visualize performance measurements.
His main takeaways:
- Important to have reproducible way to measure performance
- Visualising performance measurement helps a lot
- Always look at high level picture of the program when optimizing code
Links:
More Modern CMake - Working with CMake 3.12 and later (Deniz Bahadir)

Deniz Bahadir started by defining traditional CMake, modern CMake and more modern CMake:
- Traditional CMake (version < 3.0)
- Modern CMake (version => 3.0)
- More Modern CMake (version =>3.12)
Deniz went on to explain that CMake keep tracks of both build requirements and usage requirements. Example of build requirements are source files, compiler options, linker options and include search paths.
In traditional CMake we keep track of usage requirements with variables. In modern CMake the build targets keep track of the usage requirements themselves. In more modern CMake this new way of working also includes object library build targets.
With more modern CMake one should create a target first without sources and later add build- and usage requirements using target_... commands. A target can be an application or a library. Below is an example from Deniz GitHub account where the target_link_libraries command is used to set MyCalc::basicmath and Boost::program_options as build requirements for the FreeCalculator executable target:
// Freely available calculator app.
add_executable( FreeCalculator )
target_sources( FreeCalculator PRIVATE "src/main.cpp" )
target_link_libraries( FreeCalculator
PRIVATE MyCalc::basicmath
Boost::program_options )PRIVATE adds a build requirement for the target whereas INTERFACE adds a usage requirement. PUBLIC means that the requirement is both a build requirement and a usage requirement. The following example from Deniz GitHub account makes use of all three for the target basicmath_ObjLib.
// An OBJECT-library, used to only compile common sources once
// which are used in both math-libraries.
add_library( basicmath_ObjLib OBJECT )
target_sources( basicmath_ObjLib
PRIVATE "src/BasicMath.cpp"
"src/HeavyMath.cpp" # Takes loooooong to compile!
PUBLIC "${CMAKE_CURRENT_SOURCE_DIR}/include/Math.h"
INTERFACE "${CMAKE_CURRENT_SOURCE_DIR}/include/MathAPI.h" )Links:
Higher order functions for ordinary C++ developers (Björn Fahller)

Björn Fahller explained that a higher order function takes other functions as arguments and return functions.
One take away from Björn is to use the auto keyword to create functions that returns lambdas. Example:
template <typename T>
auto equals(T key)
{
return [key](auto const& x){ return x == key; };
}std::function can also be used but is not quite as generic.
Björn has written a library named lift that contains a number of higher order functions.
Simon Brand has written a variant of std::optional that allows functional style syntax and removed the need for many conditionals.
Links:
- Boost.HOF
- lift by Björn Fahller
- optional by Simon Brand
- https://optional.tartanllama.xyz
- Standards proposal P0798r0: Monadic operations for std::optional
C++ Concepts and Ranges - How to use them? (Mateusz Pusz)

Mateusz Pusz talked about concepts and ranges. Mateusz showed the concept syntax agreed on at Toronto 2017.
Define a concept name Sortable
template<class T>
concept Sortable { /* .... */ }Use a concept in a template function
template<typename T>
requires Sortable<T>
void sort(T&);There is also a shorthand notation
template<Sortable T>
void sort(T&);He argues that one shall use algorithms from std::ranges instead of from namespace std.
Links:
Day 3 (Saturday)
Initialisation in modern C++ (Timur Doumler)

Timur Doumler talked about different ways to do initialisation. He started with initialisation in C. He went on and described what other initialisation alternatives that were added in C++98, C++11, C++14 and C++17.
The initialisation recommendations from Timur for C++17 are:
- Use
auto - Use
= valuefor simple value types (e.g. int) - Use
= {args}for aggregate-init,std::initializer_list, DMI ctors - Use
{}for value-init - Use
(args)to call constructors that take arguments
Timur has created a handy table showing initialisation alternatives in C++17. The table is available in a tweet from Timur.
Compile Time Regular Expressions (Hana Dusíková)

Hana Dusíková talked about a Compile Time Regular Expressions (CTRE) library that she has created.
Hana has compared runtime matching performance of CTRE with other regular expression libraries such as gnu-egrep, PCRE2, std::regex, RE2 and boost. CTRE has the best runtime matching performance of those. The compile time of CTRE is slower than gnu-egrep, PCRE2 and boost but the difference is not big.
Links:
Policy-based design in C++20 (Goran Arandjelovic)

Goran Arandjelovic talked about Policy-based design in C++20.
Links:
Lightning talks
Jens Weller held a lightning talk among others. He talked about the principles behind so called brutalist web design.
Closing Keynote: 50 Shades of C++ (Nicolai Josuttis)
Nicolai Josuttis delivered the closing keynote. One of his messages was that there no single C++ style.
He talked about different ways to do initialization. Nicolai also talked about Almost Always Auto.
He designed a class that started out simple with a few setters and getters. He than gradually showed how it became quite complex if you want to optimize the setters and getters with respect to whether one should use copy by value, copy by reference or copy by value with move semantics.
Nicolai also discussed the standardisation process in the C++ committee where he mentioned the Virginia Satir Change Model among other things.
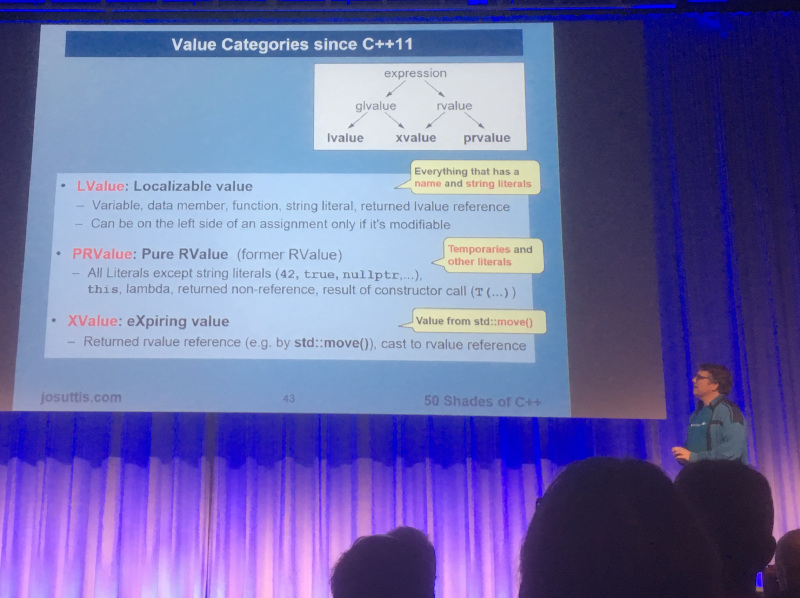
Nicolai also explained how value categories have evolved starting with K&R C and ANSI and going to C++11 and C++17:
Value categories in C++11 can be thought of as:
- LValue is “everything that ha a name and string literals”
- PRValue are “temporaries and other literals”
- XValue is a “value from std::move()”
The C++ draft currently (2019-01-17) has the following definitions:
A glvalue is an expression whose evaluation determines the identity of an object, bit-field, or function.
A prvalue is an expression whose evaluation initializes an object or a bit-field, or computes the value of an operand of an operator, as specified by the context in which it appears.
An xvalue is a glvalue that denotes an object or bit-field whose resources can be reused (usually because it is near the end of its lifetime).
Links: